This page is a translation of the original work by Devi Parikh and Kristen Grauman that can be found at https://www.cc.gatech.edu/~parikh/relative.html
Atrybuty Względne
Zwycięzca nagrody Marr (Best Paper Award), ICCV 2011
autorstwa Devi Parikh i Kristen Grauman
„Kto w tęczy może narysować linię, w której kończy się fioletowe zabarwienie, a zaczyna pomarańczowe? Wyraźnie widzimy różnicę kolorów, ale gdzie dokładnie ten pierwszy łączy się z tym drugim? Tak samo jak z rozsądkiem i szaleństwem.”
- Herman Melville, Billy Budd

Abstrakt
Nazwane przez człowieka „atrybuty” wizualne mogą być korzystne dla różnych zadań rozpoznawania. Jednak istniejące techniki ograniczają te właściwości do określonych etykiet (na przykład osoba „uśmiecha się” lub nie, scena jest „sucha” lub nie), a zatem nie wychwytują bardziej ogólnych relacji semantycznych. Proponujemy modelowanie atrybutów względnych. Biorąc pod uwagę dane treningowe określające relacje między obiektami / scenami według różnych atrybutów, uczymy się funkcji klasyfikującej każdy atrybut. Wyuczone funkcje klasyfikujące przewidują względną siłę każdego atrybutu w nowatorskich obrazach. Następnie budujemy model bazowy na wspólnej przestrzeni wyników klasyfikacji atrybutów i proponujemy nowatorską formę uczenia się od zera, w której superwizor wiąże niewidzialną kategorię obiektów z wcześniej widzianymi obiektami za pomocą atrybutów (na przykład „niedźwiedzie są bardziej futerkowe niż żyrafy ”). Ponadto pokazujemy, w jaki sposób proponowane atrybuty względne umożliwiają bogatsze opisy tekstowe nowych obrazów, które w praktyce są bardziej precyzyjne dla ludzkiej interpretacji. Pokazujemy podejście do zestawów danych twarzy i naturalnych scen oraz pokazujemy jego wyraźną przewagę nad tradycyjną predykcją atrybutów binarnych dla tych nowych zadań.
Cel
Atrybuty binarne są restrykcyjne i mogą być nienaturalne. W powyższych przykładach, chociaż obraz w lewym górnym i prawym górnym rogu można scharakteryzować odpowiednio jako naturalny i wytworzony przez człowieka, co opisalibyście ten obraz w środkowym górnym rogu? Jedynym sensownym sposobem scharakteryzowania go jest w odniesieniu do innych obrazów: jest mniej naturalny niż obraz po lewej stronie, ale bardziej niż obraz po prawej stronie.
Proponowane rozwiązanie
W tej pracy proponujemy modelowanie atrybutów względnych. W przeciwieństwie do przewidywania obecności atrybutu, atrybut względny wskazuje siłę atrybutu na obrazie w stosunku do innych obrazów. Oprócz tego, że są bardziej naturalne, atrybuty względne oferują bogatszy tryb komunikacji, umożliwiając w ten sposób dostęp do bardziej szczegółowego nadzoru człowieka (a więc potencjalnie wyższej dokładności rozpoznawania), a także możliwość generowania bardziej szczegółowych opisów nowych obrazów.
Opracowujemy podejście, które uczy się funkcji rankingu dla każdego atrybutu, biorąc pod uwagę względne ograniczenia podobieństwa w parach przykładów (lub bardziej ogólnie częściowe uporządkowanie w niektórych przykładach). Wyuczona funkcja rankingu może oszacować rangę o wartościach rzeczywistych dla obrazów wskazującą względną siłę obecności atrybutu w nich.
Wprowadzamy nowe formy uczenia się od zera i opis obrazu, które wykorzystują przewidywania względnych atrybutów.
Podejście
Uczenie się atrybutów względnych: Każdy atrybut względny uczy się poprzez się formułowanie klasyfikacji, pod nadzorem porównawczym, jak pokazano na poniższych wzorach:

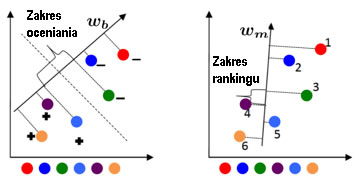
Rozróżnienie między uczeniem się funkcji szerokopasmowego rankingu (po prawej), która wymusza pożądane uporządkowanie punktów treningowych (1-6), a szerokopasmowym klasyfikatorem binarnym (po lewej), który oddziela tylko dwie klasy (+ i -) i robi niekoniecznie zachowuje pożądane uporządkowanie w punktach jest przedstawione poniżej:
Nowatorskie uczenie się od zera: badamy następującą konfigurację:
- N wszystkich kategorii: S widziane kategorie (powiązane obrazy są dostępne) + U niewidziane kategorie (żadne zdjęcia nie są dostępne dla tych kategorii)
- S widziane kategorie są opisywane względem siebie za pomocą atrybutów (nie wszystkie pary kategorii muszą być powiązane dla wszystkich atrybutów)
- U niewidziane kategorie opisano w odniesieniu do (podzbioru) widzialnych kategorii w kategoriach (podzbiór) atrybutów.
Najpierw trenujemy zestaw atrybutów względnych, korzystając z nadzoru przewidzianego dla widzianych kategorii. Atrybuty te można również wstępnie wyszkolić na podstawie danych zewnętrznych. Następnie budujemy model generatywny (Gaussa) dla każdej widzianej kategorii, wykorzystując odpowiedzi względnych atrybutów na obrazy z widzianych kategorii. Następnie wywnioskujemy parametry modeli bazowych niewidzianych kategorii, wykorzystując ich względne opisy w odniesieniu do widzianych kategorii. Wizualizację prostego podejścia, które stosujemy w tym celu, pokazano poniżej:
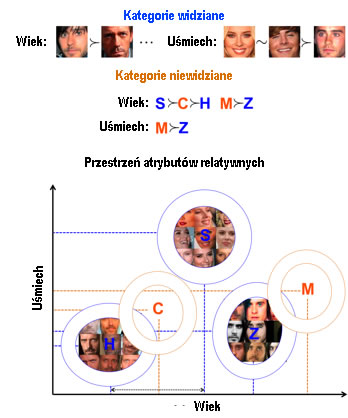
Obraz testowy jest przypisany do kategorii z najwyższym prawdopodobieństwem.
Automatyczne generowanie względnych opisów tekstowych obrazów: Biorąc pod uwagę obraz I, który zostanie opisany, oceniamy wszystkie wyuczone funkcje rankingu na I. Dla każdego atrybutu identyfikujemy dwa obrazy referencyjne leżące po obu stronach I i nie są zbyt daleko ani zbyt blisko do I. Obrazek I jest następnie opisany w odniesieniu do tych dwóch obrazów referencyjnych, jak pokazano poniżej:
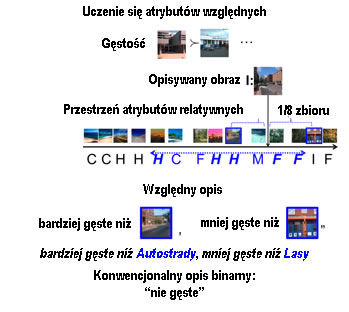
Jak widać powyżej, oprócz opisywania obrazu w stosunku do innych obrazów, nasze podejście może również opisywać obraz w stosunku do innych kategorii, co skutkuje opisem czysto tekstowym. Oczywiste jest, że opisy względne są bardziej precyzyjne i informacyjne niż konwencjonalny opis binarny.
Eksperymenty i jego wyniki
Przeprowadzamy eksperymenty na dwóch zestawach danych:
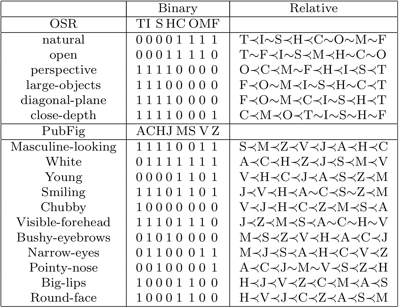
(1) Rozpoznawanie Sceny Na Zewnątrz (Outdoor Scene Recognition - OSR) zawierające 2688 zdjęć z 8 kategorii: wybrzeże C, las F, autostrada H, śródmieście I, góra M, otwarte kraj O, ulica S i wysoki budynek T. Używamy funkcji gist by przedstawić obrazy.
(2) Podzbiór publicznej bazy danych twarzy (Public Figures Face Database - PubFig) zawierający 772 obrazy z 8 kategorii: Alex Rodriguez A, Clive Owen C, Hugh Laurie H, Jared Leto J, Miley Cyrus M, Scarlett Johansson S, Viggo Mortensen V i Zac Efron Z. Używamy połączonych funkcji koloru i koloru do przedstawienia obrazów.
Listę atrybutów używanych dla każdego zestawu danych wraz z adnotacjami binarnymi i względnymi atrybutami pokazano poniżej:
Uczenie się od zera:
Porównujemy nasze proponowane podejście do dwóch poziomów bazowych. Pierwszym z nich są oparte na wynikach atrybuty względne (SRA). Ta linia bazowa jest taka sama jak nasze podejście, z tym wyjątkiem, że wykorzystuje wyniki binarnego klasyfikatora (atrybuty binarne) zamiast wyników funkcji rankingu. Ta linia bazowa pomaga ocenić potrzebę funkcji rankingu w celu najlepszego modelowania atrybutów względnych. Naszym drugim punktem odniesienia jest model przewidywania bezpośredniego atrybutu (DAP) wprowadzony przez Lamperta i in. w CVPR 2009. Ten punkt odniesienia pomaga ocenić korzyści wynikające z względnego traktowania atrybutów w porównaniu z kategorycznym. Oceniamy te podejścia pod kątem różnej liczby niewidzialnych kategorii, różnej ilości danych wykorzystywanych do trenowania atrybutów, różnej liczby atrybutów używanych do opisywania niewidocznych kategorii oraz różnych poziomów „luźności” w opisie niewidzialnych kategorii. Szczegóły konfiguracji eksperymentalnej można znaleźć w naszym artykule. Wyniki pokazano poniżej:
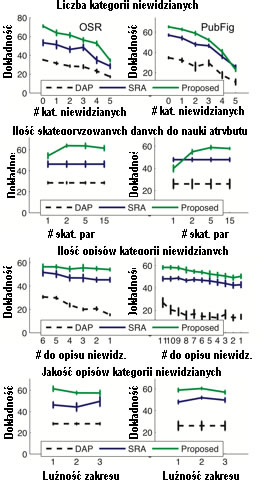
Automatycznie generowane opisów obrazów:
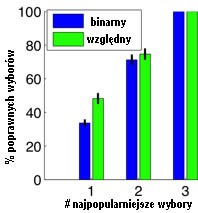
Aby ocenić jakość naszych względnych opisów obrazów w stosunku do binarnych odpowiedników, przeprowadziliśmy badanie na ludziach. Wygenerowaliśmy opis obrazu, stosując nasze podejście, a także podstawowe atrybuty binarne. Przedstawiliśmy tematom ten opis wraz z trzema zdjęciami. Jednym z trzech obrazów był opisywany obraz. Zadaniem badanych było uszeregowanie trzech obrazów, na podstawie których, jak sądzili, najprawdopodobniej zostanie opisany. Im dokładniejszy opis, tym większe szanse, że uczestnicy zidentyfikują prawidłowy obraz. Ilustracja zadania przedstawionego przedmiotom pokazano poniżej:

Wyniki badania przedstawiono poniżej. Widzimy, że badani mogą dokładniej zidentyfikować prawidłowy obraz za pomocą naszych proponowanych atrybutów względnych w porównaniu z atrybutami binarnymi.
Przykładowe binarne opisy obrazów oraz wzzględne opisy w odniesieniu do kategorii pokazano poniżej:
| Obraz |
Opis binarny |
Opis względny |
 |
nienaturalny
nieotwarty
perspektywa |
bardziej naturalny niż wysoki budynek, mniej naturalny niż las
bardziej otwarty niż wysoki budynek, mniej otwarty niż wybrzeże
więcej perspektywy niż budownictwo wysokie |
 |
nienaturalny
nieotwarty
perspektywa |
bardziej naturalne niż centrum miasta, mniej naturalne niż autostrada
bardziej otwarte niż ulica, mniej otwarte niż wybrzeże
więcej perspektywy niż autostrady, mniej perspektywy niż centrum miasta |
 |
naturalny
otwarty
perspektywa |
bardziej naturalne niż budownictwo wysokie, mniej naturalne niż góry
bardziej otwarty niż góra
mniej perspektywy niż na otwartym terenie |
 |
biały
nieuśmiechnięty
widoczne czoło |
bardziej biały niż Alex Rodriguez
bardziej uśmiechnięty niż Jared Leto, mniej uśmiechnięty niż Zac Efron
bardziej widoczne czoło niż Jared Leto, mniej widoczne niż Miley Cyrus |
 |
biały
nieuśmiechnięty
niewidoczne czoło |
bardziej biały niż Alex Rodriguez, mniej biały niż Miley Cyrus
mniej uśmiechnięty niż Hugh Laurie
bardziej widoczne czoło niż Zac Efron, mniej widoczne niż Miley Cyrus |
 |
niemłody
bujne brwi
okrągła twarz |
młodszy niż Clive Owen, starszy niż Scarlett Johansson
bardziej bujne brwi niż Zac Efron, mniej bujne niż Alex Rodriguez
okrąglejsza twarz niż Clive Owen, mniej okrągła niż Zac Efron |
Dane
Zapewniamy wyuczone atrybuty względne i ich przewidywania dla dwóch zestawów danych użytych w naszym artykule: Rozpoznanie Sceny Na Zewnątrz (OSR) i podzbioru Publicznej Bazy Danych Twarzy (PubFig).
CZYTAJ TO
Pliki do pobrania (v2)
Zestaw Danych Względnych Atrybutów Twarzy. Zawiera adnotacje dla 29 atrybutów względnych dla 60 kategorii z publicznej bazy danych twarzy (PubFig).
Kod
Zmodyfikowaliśmy implementację RankSVM Oliviera Chappelle'a, aby trenować atrybuty względne z ograniczeniami podobieństwa. Nasz zmodyfikowany kod można znaleźć tutaj.
Jeśli korzystasz z naszego kodu, zacytuj następujący artykuł:
D. Parikh i K. Grauman
"Relative Attributes"
International Conference on Computer Vision (ICCV), 2011.
Dema
Przykłady różnych zastosowań atrybutów względnych można znaleźć tutaj. Opis tych aplikacji można znaleźć w dokumentach tutaj.
Publikacje
Po pełną listę publikacji związanych z tematem przejdź do strony źródłowej.